深入探討實時決策與控制:驅動 AI 系統的智慧大腦
在自動駕駛、機器人、智慧製造、航空航太以及許多 Physical AI 應用中,系統不僅需要精準感知周圍環境,更關鍵的是要能在極短的時間內,根據不斷變化的資訊,做出最佳的行動決策並精確執行。這就是實時決策與控制的核心挑戰。它運用強化學習 (Reinforcement Learning, RL) 與預測控制 (Model Predictive Control, MPC) 等先進演算法,確保 AI 系統在動態環境中能迅速、安全地做出最佳決策。
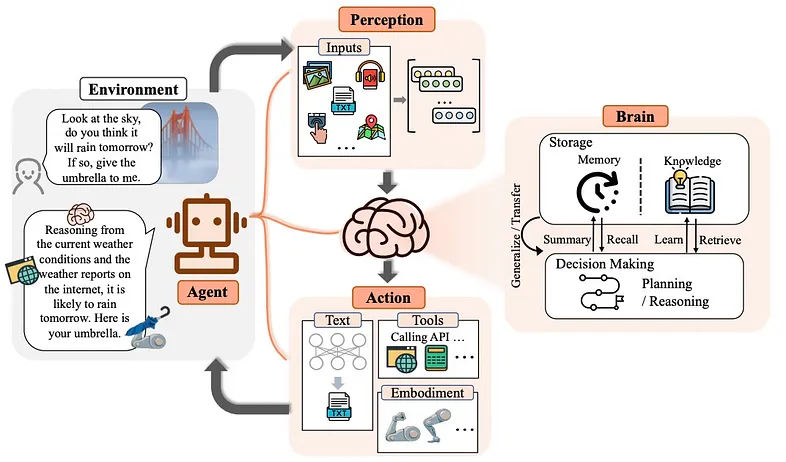
實時決策與控制是 AI 系統自主運行的核心環節。
實時決策的重要性與挑戰
實時決策之所以重要,是因為許多真實世界的應用場景具有以下特性:
- 動態性: 環境不斷變化,物體移動,情況複雜。
- 不確定性: 感測器數據可能不完整或有噪音,未來事件難以完全預測。
- 時間緊迫性: 決策必須在毫秒或微秒級別完成,否則可能導致嚴重後果(如碰撞)。
- 複雜的目標與約束: 需要同時考慮多個目標(如效率、舒適度)和約束(如安全、法規)。
傳統的基於規則或預編程的控制方法難以應對這種複雜性,因此需要更智慧、更具適應性的 AI 演算法。
強化學習 (Reinforcement Learning, RL) 在決策中的應用
強化學習是一種讓 AI 透過與環境互動「學習」如何做出最佳決策的方法。它包括:
- 代理人 (Agent): 執行決策的 AI 系統(例如自動駕駛汽車、機器人)。
- 環境 (Environment): 代理人所處的實體世界或模擬器。
- 狀態 (State): 環境當前的狀況(例如汽車的速度、位置、周圍交通情況)。
- 行動 (Action): 代理人可以執行的操作(例如加速、減速、轉向)。
- 獎勵 (Reward): 代理人執行某個行動後,環境給予的回饋信號(例如安全抵達目的地為正獎勵,發生碰撞為負獎勵)。
RL 代理人的目標是學習一個策略 (Policy),使得在長期內獲得的總獎勵最大化。在實時決策中,RL 的優勢在於:
- 自主學習: 無需人工編程所有行為,系統可透過試錯和經驗學習複雜的行為。
- 適應性: 在面對未知或動態環境時,能自我調整策略以應對變化。
- 最佳化: 能在多個相互衝突的目標之間找到平衡點。
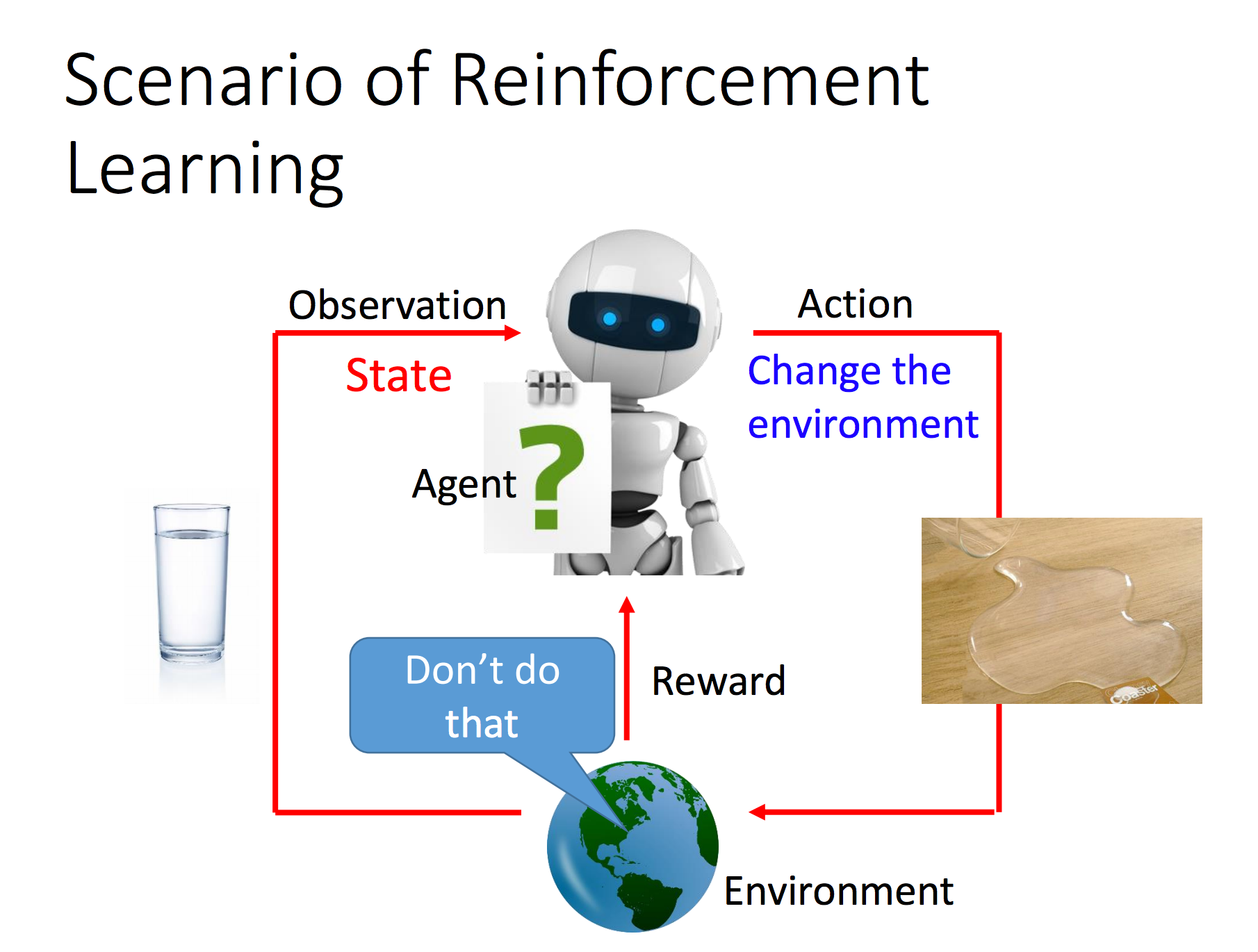
強化學習透過不斷的試錯與獎勵回饋來優化決策策略。
預測控制 (Model Predictive Control, MPC) 在控制中的應用
預測控制是一種控制策略,它在每個時間步長都會:
- 預測: 基於系統的動態模型和當前狀態,預測未來一段時間內系統的行為。
- 最佳化: 找到一系列最佳的控制行動,使得在預測期內某個成本函數(例如誤差最小化、能耗最低、安全性最高)達到最佳。
- 執行: 只執行最佳控制序列中的第一個行動。
- 重覆: 系統前進一個時間步長,然後重新進行預測和最佳化。
MPC 的優勢在於:
- 處理約束: 能明確處理系統的實體約束(例如速度限制、轉向角度限制),確保安全性。
- 前瞻性: 考慮未來的行為,避免短期最佳化導致的長期問題。
- 多變數控制: 能同時控制多個輸入和輸出變數。
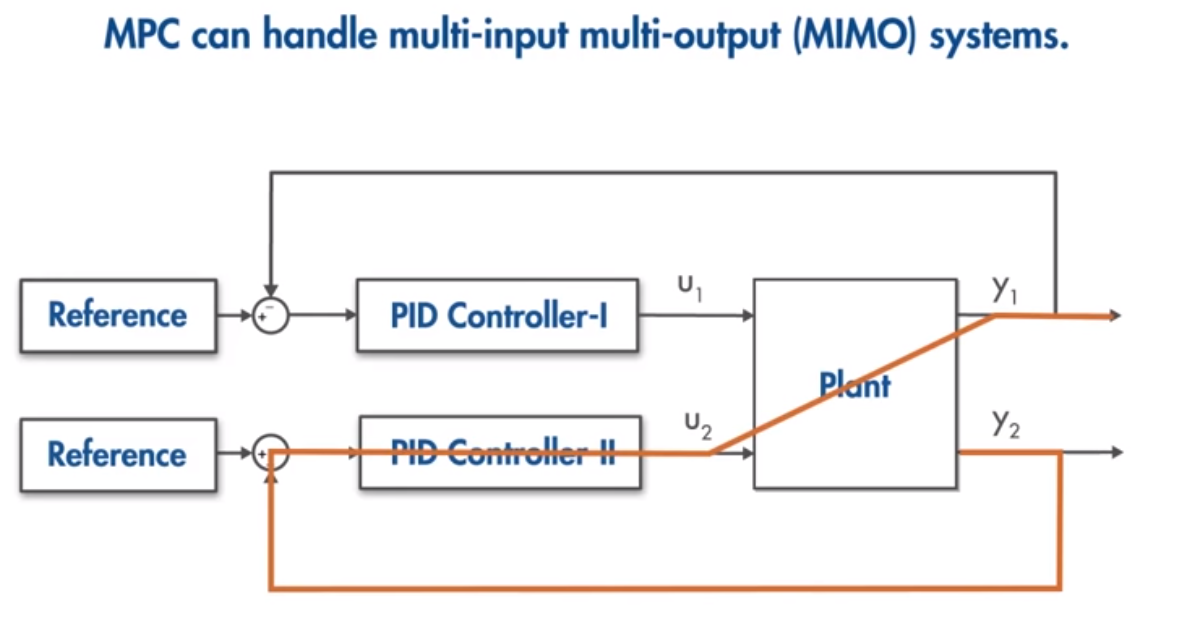
模型預測控制透過預測未來行為來實現精確且符合約束的控制。
RL 與 MPC 的結合
在許多先進的 AI 系統中,RL 和 MPC 並非互相排斥,而是可以相互補充:
- RL 學習高層次策略: RL 可以學習複雜、抽象的決策,例如在自動駕駛中何時變道、何時超車。
- MPC 執行低層次控制: MPC 可以基於 RL 的高層次指令,精確地控制車輛的油門、剎車和轉向,同時考慮實體約束和舒適度。
- RL 學習模型: RL 甚至可以用來學習或改進 MPC 所需的系統動態模型,使其在不同情境下更準確。
這種結合使得 AI 系統既能展現高度智慧和適應性,又能保證實體執行的精確性和安全性。
應用場景
實時決策與控制技術是許多 Physical AI 應用不可或缺的一部分:
- 自動駕駛: 從車道保持、自動變道到緊急避障,所有動作都需實時決策與精確控制。
- 機器人: 工業機器人的協作、服務機器人的自主導航與人機互動,都需要毫秒級的反應。
- 無人機: 飛行路徑規劃、避障、精準降落,皆依賴實時決策與控制。
- 智慧電網: 實時調整能源分配,應對突發需求或供應變化。
隨著計算能力的提升和演算法的創新,實時決策與控制將持續推動 AI 系統向更高度的自主化和智能化發展。
實時決策與控制實戰課程:循序漸進的學習路徑
本課程旨在引導學員從控制系統與最佳化基礎入門,逐步深入到強化學習與模型預測控制的進階理論與實踐,最終能夠設計並實作具備實時決策與控制能力的 AI 系統。
第一階段:控制系統與最佳化基礎 (入門級)
建立對自動控制與最佳化理論的基本認識,為後續進階學習打下基礎。
- 課程目標: 理解控制系統的基本概念、數學模型與基礎最佳化方法。
- 內容概述:
- 自動控制概論: 開迴路/閉迴路控制、回饋控制原理。
- 系統建模: 狀態空間表示、傳遞函數、線性/非線性系統。
- 基礎控制策略: PID 控制器設計與調參。
- 最佳化基礎: 梯度下降、凸最佳化概念。
- 實作練習: 模擬 PID 控制器控制簡單系統 (如倒立擺、馬達速度)。
- 建議工具: Python (NumPy, SciPy, Matplotlib), MATLAB/Simulink。
第二階段:強化學習核心概念與演算法 (進階)
深入學習強化學習的原理,掌握經典演算法及其應用。
- 課程目標: 熟悉強化學習的框架,能夠實作並應用基礎 RL 演算法解決決策問題。
- 內容概述:
- RL 框架: 代理人、環境、狀態、行動、獎勵、策略、價值函數。
- 馬可夫決策過程 (MDP): 定義與屬性。
- 動態規劃: 價值迭代 (Value Iteration)、策略迭代 (Policy Iteration)。
- 蒙地卡羅方法: 預測與控制。
- 時序差分學習 (TD Learning): SARSA、Q-learning。
- 深度強化學習入門: DQN (Deep Q-Network) 概念。
- 實作練習: 解決經典控制問題 (如 CartPole、FrozenLake) 使用 Q-learning 或 DQN。
- 建議工具: Python (Gym, Stable Baselines3), TensorFlow/PyTorch。
第三階段:模型預測控制與進階最佳化 (專業級)
學習模型預測控制的理論與實作,處理複雜系統約束。
- 課程目標: 掌握 MPC 的核心原理,能夠設計並實現考慮約束的最佳化控制器。
- 內容概述:
- MPC 原理: 預測模型、成本函數、約束處理、最佳化問題。
- 線性 MPC: 線性系統的預測控制設計與實作。
- 非線性 MPC (NMPC): 非線性系統的處理方法、最佳化求解器 (如 IPOPT, OSQP)。
- 狀態估計與濾波: 擴展卡爾曼濾波 (EKF)、無跡卡爾曼濾波 (UKF) 在狀態估計中的應用。
- 實作練習: 設計並實作一個簡單的車輛路徑追蹤 MPC 控制器,考慮速度和轉向約束。
- 建議工具: Python (CasADi, CVXPY), C++ (Eigen, Ceres Solver), MATLAB (MPC Toolbox)。
第四階段:實時系統整合與高階應用 (專家級)
將所學知識應用於實際的實時系統,並探索前沿技術與挑戰。
- 課程目標: 具備獨立設計、開發和調試複雜實時決策與控制系統的能力,理解產業最新趨勢。
- 內容概述:
- RL 與 MPC 融合策略: 分層控制架構、基於模型的強化學習 (Model-based RL)、RL for MPC (學習模型或控制器參數)。
- 實時系統考量: 計算效率、延遲管理、硬體加速 (GPU, FPGA)。
- 安全與魯棒性: 安全強化學習、故障診斷與容錯控制。
- 多代理系統: 多機器人協同控制、分散式決策。
- 應用案例深入分析: 自動駕駛決策堆疊、工業機器人協作、無人機自主飛行。
- 實作專案: 開發一個模擬或實際的自主導航系統,整合 RL 進行高層次決策,MPC 進行低層次控制。
- 建議工具: ROS (Robot Operating System), 各種感測器與執行器硬體, 模擬器 (如 Gazebo, Carla), 邊緣計算平台。